| Psychology 105 | Richard Lowry ©1999-2002 |
Among the states near the top of the list in 1993 (verbal and math SAT averages combined) were Iowa, weighing in at 1103; North Dakota, at 1101; South Dakota, at 1060, and Kansas, at 1042. And down near the bottom were the oft-maligned "rust belt" states of the northeast: Connecticut, at 904; Massachusetts, at 903; New Jersey, at 892; and New York, more that 200 points below Iowa, at 887. You can easily imagine the joy in DesMoines and Topeka that day, and the despair in Trenton and Albany. For surely the implication is clear: The state educational systems in Iowa, North Dakota, South Dakota, and Kansas must have been doing something right, while those in Connecticut, Massachusetts, New Jersey, and New York must have been doing something not so right.
Powell, B., & Steelman, L. C. "Bewitched, bothered, and bewildering: The uses and abuses of SAT and ACT scores." Harvard Educational Review,66, 1, 27—54.
See also Powell, B., & Steelman, L. C. "Variations in state SAT performance: Meaningful or misleading?" Harvard Educational Review,54, 4, 389—412.
| State | Percentage taking SAT | Average SAT score Iowa | North Dakota South Dakota Kansas 5 | 6 6 9 1103 | 1101 1060 1042 Connecticut | Massachusetts New Jersey New York 88 | 81 76 74 904 | 903 892 887 |
|
|
|
State | Xi Percentage taking SAT | Yi Average SAT score 1i | 2i ::::i 49i 50i X1 | X2 ::::i X49 X50 Y1 | Y2 ::::i Y49 Y50 |
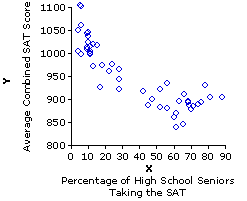
| The next step in bivariate coordinate plotting is to lay out two axes at right angles to each other. By convention, the horizontal axis is assigned to the X variable and the vertical axis to the Y variable, with values of X increasing from left to right and values of Y increasing from bottom to top. | 
|
|
| In Figure 6.1b the X axis does begin at zero, because any value much larger than that would lop off the lower end of the distribution of Xi values; whereas the Y axis begins at 800, because the lowest observed value of Yi is 838. |
| Toggle!
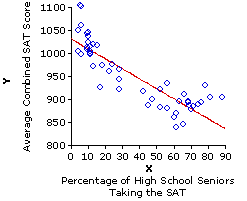
Actually, in this particular example there are two somewhat different patterns that the 50 state data points could be construed as fitting. The first is the pattern delineated by the solid downward slanting straight line, and the second is the one marked out by the dotted and mostly downward sloping curved line that you will see if you click the line labeled "Toggle!" [Click "Toggle!" again to return to the straight line.] |
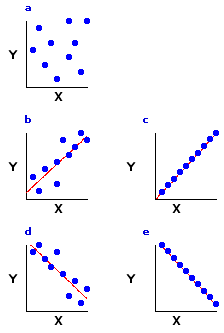 | The limiting case of linear correlation, as illustrated in Figures 6.2c and 6.2e, is when the data points line up along the diagonal like beads on a taut string. This arrangement, typically spoken of as perfect correlation, would represent the maximum degree of linear correlation, positive or negative, that could possibly exist between two variables. In the real world you will normally find perfect linear correlations only in the realm of basic physical principles; for example, the relationship between voltage and current in an electrical circuit with constant resistance. Among the less tidy phenomena of the behavioral and biological sciences, positive and negative linear correlations are much more likely to be of the "imperfect" types illustrated in Figures 6.2b and 6.2d. |