b
c
d
e
f
2
3
4
5
6
2
4
10
12
8
| Psychology 105 | Richard Lowry ©1999-2002 |
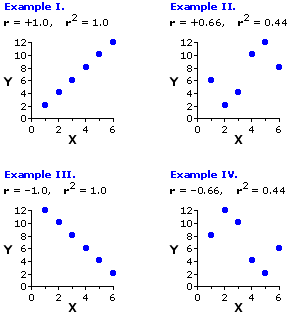
|
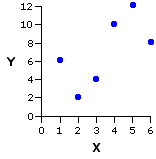
Pair | Xi | Yi |
| |
| a b c d e f | 1 2 3 4 5 6 | 6 2 4 10 12 8 |
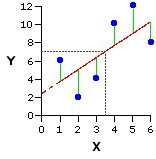
| As it happens, this line of best fit will in every instance pass through the point at which the mean of X and the mean of Y intersect on the graph. In the present example, the mean of X is 3.5 and the mean of Y is 7.0. Their point of intersection occurs at the convergence of the two dotted gray lines. |
| r = |
observed covariance maximum possible positive covariance
| | |||
| For any n numerical values, a, b, c, etc., the geometric mean is the nth root of the product of those values. Thus, the geometric mean of a and b would be the square root of axb; the geometric mean of a, b and c would be the cube root of axbxc; and so on. |
| r = |
observed covariance sqrt[(varianceX) x (varianceY)]
| | |||
| Recall that "sqrt" means "the square root of." |
| In order to get from the formula above to the one below, you will need to recall that the variance (s2) of a set of values is simply the average of the squared deviates: SS/N. |
| r = |
SCXY sqrt[SSX x SSY]
| | |||
| To understand this kinship, recall from Part 4 precisely what is meant by the term "deviate." |
|
For any particular item in a set of measures of the variable X, Similarly, for any particular item in a set of measures of the variable Y, |
| As you have probably already guessed, a co-deviate pertaining to a particular pair of XY values involves the deviateX of the Xi member of the pair and the deviateY of the Yi member of the pair. The specific way in which these two are joined to form the co-deviate is |
co-deviateXY = (deviateX) x (deviateY) |
| And finally, the analogy between a co-deviate and a squared deviate: |
For a value of Xi, the squared deviate is For a value of Yi it is And for a pair of Xi and Yi values, the co-deviate is |
| r = |
observed covariance maximum possible positive covariance
| | |||
| r = |
SCXY sqrt[SSX x SSY]
| | |||
|
Pair | Xi | Yi | Xi2 | Yi2 | XiYi |
| ||||||||||||||
| a b c d e f | 1 2 3 4 5 6 | 6 2 4 10 12 8 | 1 4 9 16 25 36 | 36 4 16 100 144 64 | 6 4 12 40 60 48 sums | 21 | 42 | 91 | 364 | 170 |
| | ||||||||
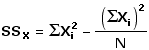
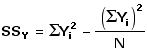
| r = |
SCXY sqrt[SSX x SSY]
|
| = |
23.0 | sqrt[17.5 x 70.0] = +0.66 |
| | |||||||
r2 = (+0.66)2 = 0.44 |
Sums of| Xi | Yi |
| Xi2 | Yi2 |
| XiYi | 1,816 | 47,627 | 102,722 | 45,598,101 | 1,650,185 | | ||||||