| Psychology 105 | Richard Lowry ©1999-2002 |
|
|
variance = (standard deviation)2 standard deviation = sqrt[variance] | Note: Owing to the limitations of HTML coding for a web document, we will not be able to use the conventional radical sign to indicate "square root of." We will instead be using the notation "sqrt." Thus sqrt[variance] means "the square root of the variance," sqrt[16] means 'the square root |
deviate = Xi — MX |
squared deviate = (Xi — MX)2 sum of squared deviates: SS = |
| s2 = | N | = | SS N |
| s = | sqrt | [ | N | ] | = sqrt | [ | SS N | ] |
|
| Xi | deviate = (Xi — MX) | squared deviate (Xi — MX)2 |
sum of squared deviates: SS = 10 variance: s2 = SS/N = 10/5 = 2 standard deviation: s = square_root(variance) = square_root(2) = +1.41 1 | 2 3 4 5
1—3 = —2 | 2—3 = —1 3—3 = 0 4—3 = +1 5—3 = +2
4 | 1 0 1 4
| sum = | 10 | |
| SS = |
| Xi2 | The square of any particular value of Xi within the distribution. If Xi = 3, then Xi2 = 3x3 = 9; if Xi = 4, then Xi2 = 4x4 = 16; and so on.| The sum of all the squared Xi values within the distribution. If the values of Xi within a distribution are 3, 4, and 5, the sum of the squared Xi values is | The sum of the original (unsquared) values of Xi within a distribution. If the values of Xi within a distribution are 3, 4, and 5, the sum of the original (unsquared) squared Xi values is simply | The square of the value of | |
| SS = | ( 2N2 |
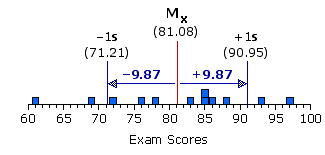
| Xi | Xi2 | sum of squared deviates: = 80,063 — [(9732)/12] = 80,063 — 78894.08 = 1168.92 variance: s2 = 1168.92/12 = 97.41 standard deviation: s = sqrt[variance] = sqrt[97.41] = +9.87
| 61 | 69 72 76 78 83 85 85 86 88 93 97 3721 | 4761 5184 5776 6084 6889 7225 7225 7396 7744 8649 9409 Sums
| 973 80,063 |